BERT的总结与梳理
在学习BERT之前,我们需要回顾一下Transformer,看一下这篇文章:Transformer总结和梳理
而BERT只包括Transformer中的Encoder结构
总体概览
本文通过以下几部分来梳理BERT
BERT的输入
BERT的结构
BERT所做的任务
BERT的输入
先放一张图片来看一下BERT的输入结构:
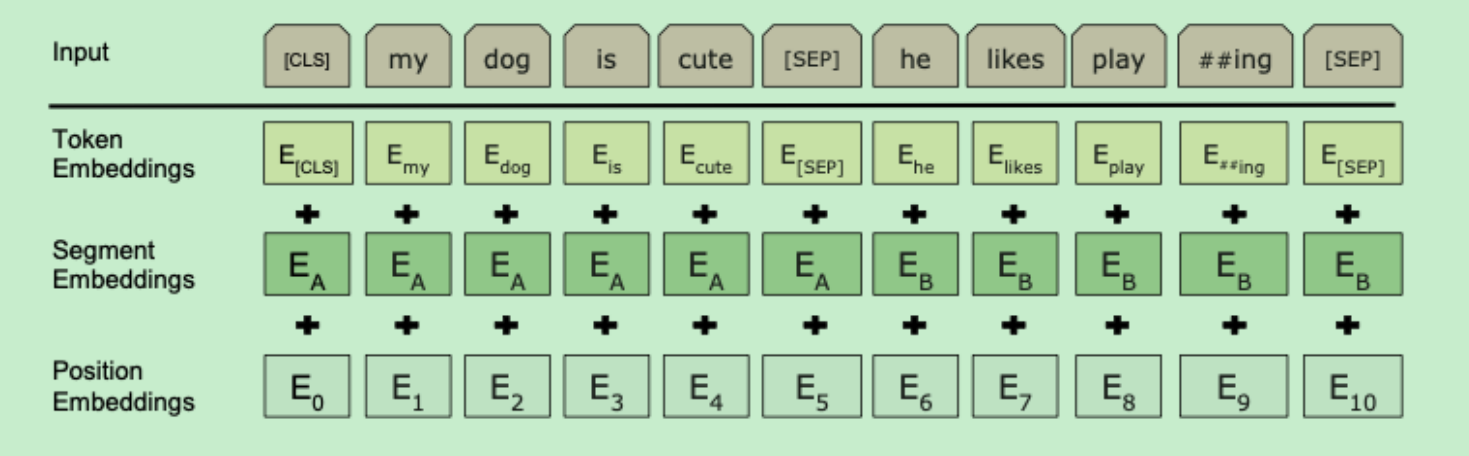
可以看出BERT的输入包括三部分:Token Embedding+Segment Embedding+Position Embedding组成
Token Embedding
Token Embedding为将原始文本转化为embedding后的结果,其shape为[N,d_model],N为seq_lenght,d_model词向量的维度
Segment Embedding
Segment Embedding为句子分割嵌入,主要用来区分前后两句话,其shape为[N,d_model],N为seq_lenght,d_model句子嵌入的维度
Position Embedding
Position Embedding为位置嵌入,用来区分token的位置,其shape为[N,d_model],N为seq_length,d_model为位置嵌入的维度,详细的Position Embedding请点击此处查看
可以看出,三种Embedding之后shape是一样的,由上图可以看出,input是将三个Embedding进行相加求和,即为输入的向量
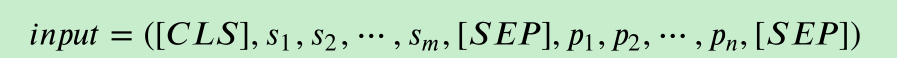
在输入BERT前还需进行修改,添加特殊token,[CLS]表示一句话的开头,s_m和p_n分别为两句话,输⼊序列⾸标记[SEP]⽤作分类任务表示;特殊标记[SEP]⽤作区分句⼦对各⼦句。
BERT的结构
整体结构
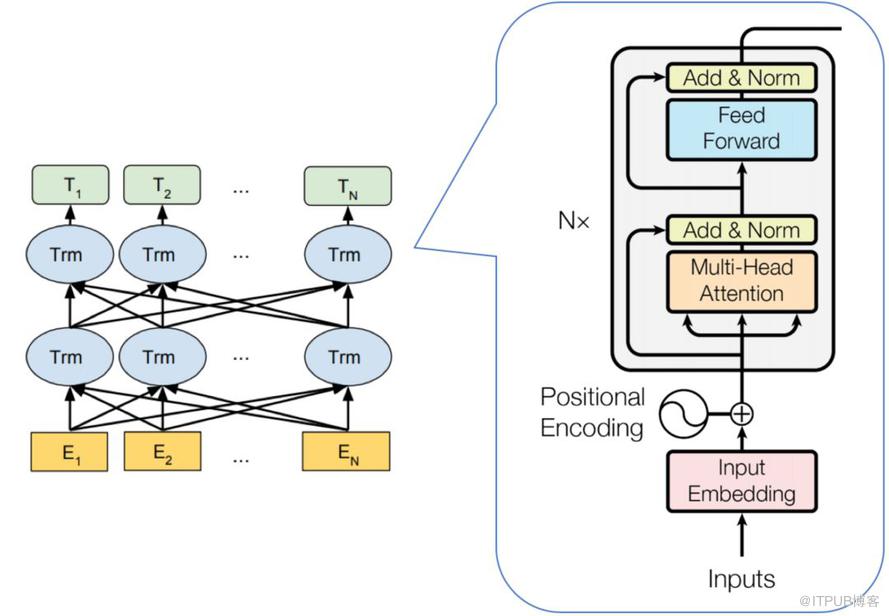
由上图可以看出:BERT是由多个Trm组成,Trm为Transformer的Encoder结构,即BERT是由多个Transformer的Encoder堆叠而成
根据堆叠的层数不同,将BERT分为两类
+ BERT-base:12层,768维度,12头,110百万参数
+ BERT-large:24层,1024维度,16头,340百万参数
单个Block
单个Block就是Transformer的Encoder,结构如下:
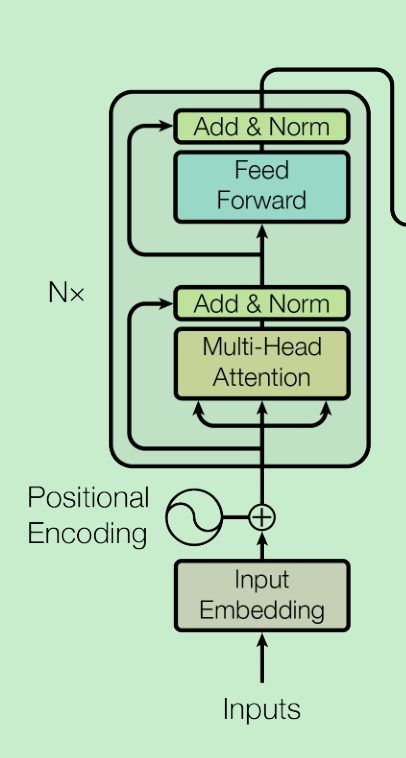
关于input输入,篇幅刚开始已经做详细介绍
多头注意力与缩放点积
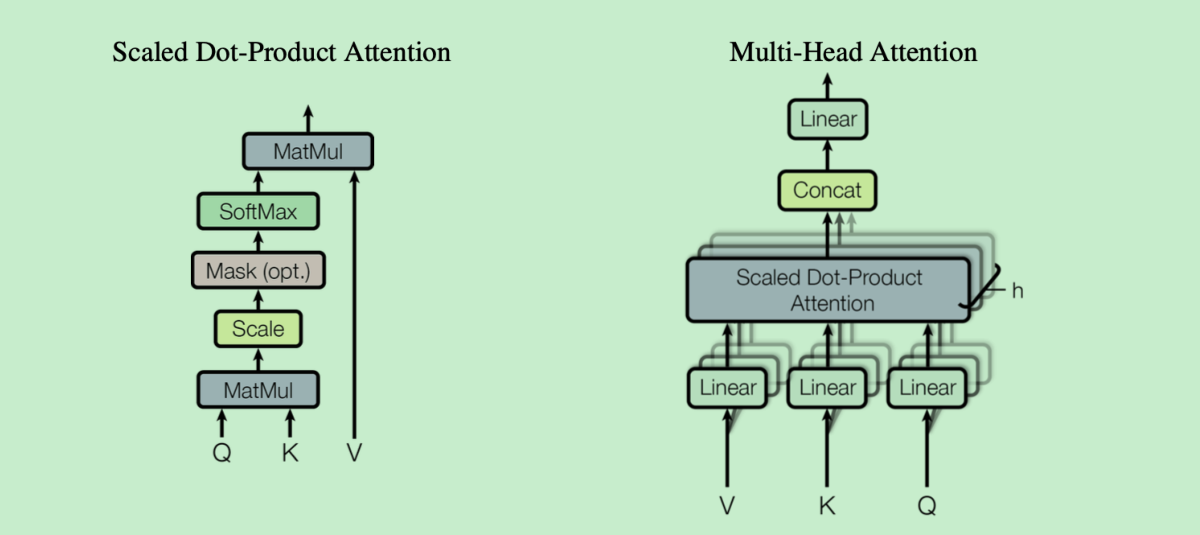
这里的多头注意力和缩放点积均和Transformer中的相同,缩放点积打分函数如下:
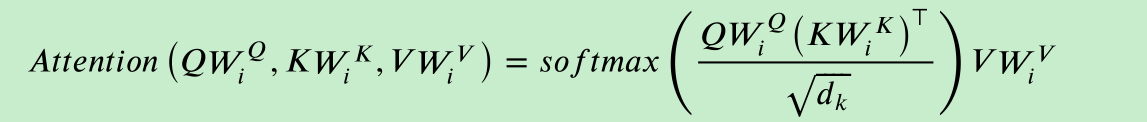
具体详细解析可以点击此处查看
ADD & Norm
关于ADD & Norm可以点击此处查看解释
前馈神经网络
FeedForward是Multi-Head Attention的输出做了残差连接和Norm之后得数据,然后FeedForward做了两次线性线性变换,为的是更加深入的提取特征。
在每次线性变换都引入了非线性激活函数Relu,在Multi-Head Attention中,主要是进行矩阵乘法,即都是线性变换,而线性变换的学习能力不如非线性变换的学习能力强,FeedForward的计算公式如下:max相当于Relu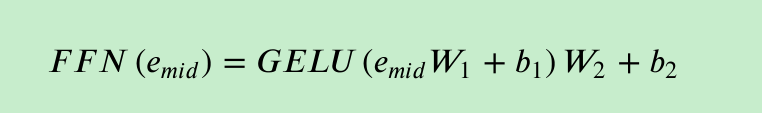
所以FeedForward的作用是:通过线性变换,先将数据映射到高纬度的空间再映射到低纬度的空间,提取了更深层次的特征
PAD掩码
对于Transformer而言,每次的输入为:[batch_size,seq_length,d_module]结构,由于句子一般是长短不一的,而输入的数据需要是固定的格式,所以要对句子进行处理。
通常会把每个句子按照最大长度进行补齐,所以当句子不够长时,需要进行补0操作,以保证输入数据结构的完整性
但是在计算注意力机制时的Softmax函数时,就会出现问题,Padding数值为0的话,仍然会影响到Softmax的计算结果,即无效数据参加了运算。
为了不让Padding数据产生影响,通常会将Padding数据变为负无穷,这样的话就不会影响Softmax函数了
BERT的两个任务
遮蔽语言模型(MLM)训练任务
遮蔽语⾔模型可描述为给定单词上下⽂序列后,当前单词出现的条件概率的乘积:
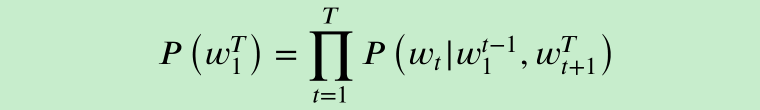
其中, $W_t$是第t个单词,$W_i^j$=($W_i$,$W_{i+1}$,………..$W_{j+1}$,$W_{j}$)是从第i个单词到第j个单词的子序列。
具体的表现形式如下:
在输入Embedding中会选择15%的单词进行MASK,再将其预测出来,MASK操作只会发生在Pre-training中,而在Fine-turning中不会出现,为了减少MASK对微调的影响,采用以下策略:
+ 80%的词会被真正[MASK]
+ 10%的次会被随机替换成其它Token
+ 10%的词保持不变
预测下个句子(NSP)任务
从语料库中⽣成⼆值化的下⼀句句⼦预测任务。
具体的,当为每个预训练选择句⼦A和B时,B的50%的时间是跟随A的实际下⼀个句⼦,⽽50%的时间是来⾃语料库的
随机句⼦。
- input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] label = IsNext
- input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are filght ##less birds [SEP] label = NotNext