Q、K点乘之后的方差会随着维度的增大而增大,而大的方差会导致极小的梯度,为了防止梯度消失,所以除以sqrt(dk)来减小方差
什么是self-attention
首先我们来看一下Transformer架构:对于input输出,首先进行input embedding,然后再进行positional encoding,将两者相加作为Encoder的输入,也就是输如X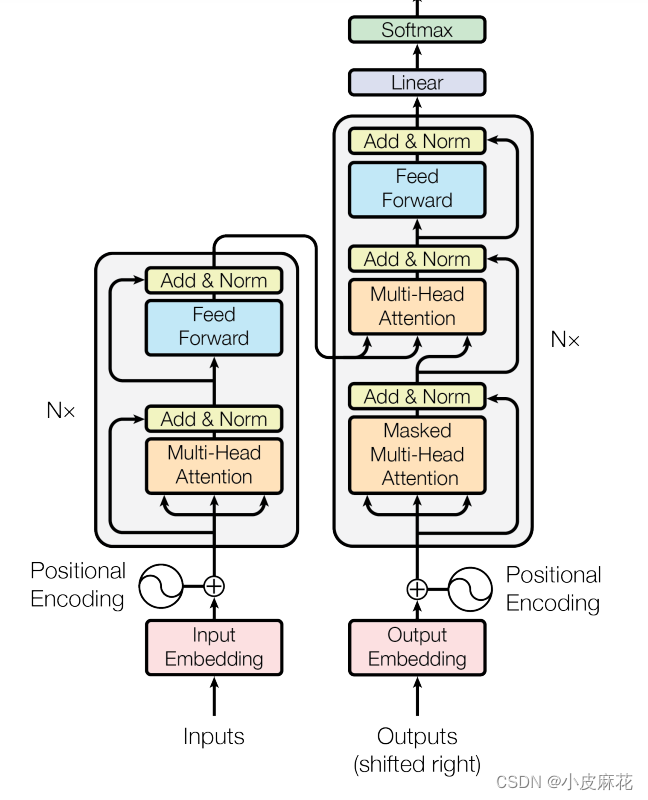
何为self-attention?首先我们要明白什么是attention,对于传统的seq2seq任务,例如中-英文翻译,输入中文,得到英文,即source是中文句子(x1 x2 x3),英文句子是target(y1 y2 y3)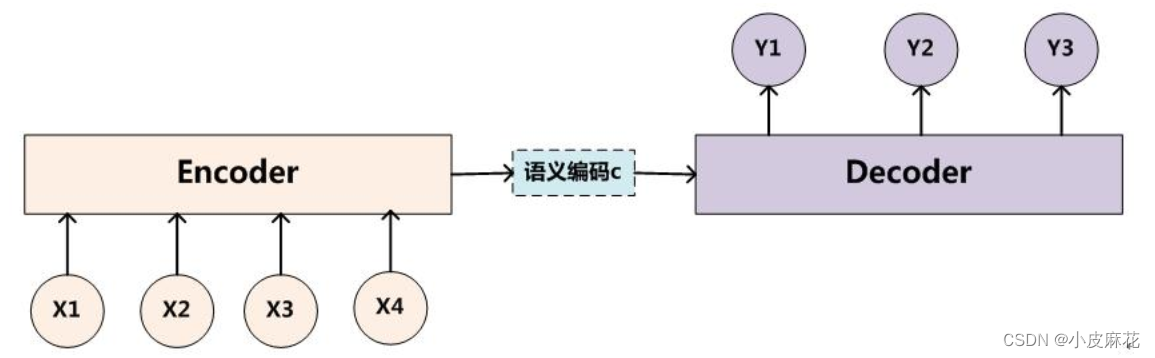
attention机制发生在target的元素和source中的所有元素之间。简单的将就是attention机制中的权重计算需要target参与,即在上述Encoder-Decoder模型中,Encoder和Decoder两部分都需要参与运算。
而对于self-attention,它不需要Decoder的参与,而是source内部元素之间发生的运算,对于输入向量X,对其做线性变换,分别得到Q、K、V矩阵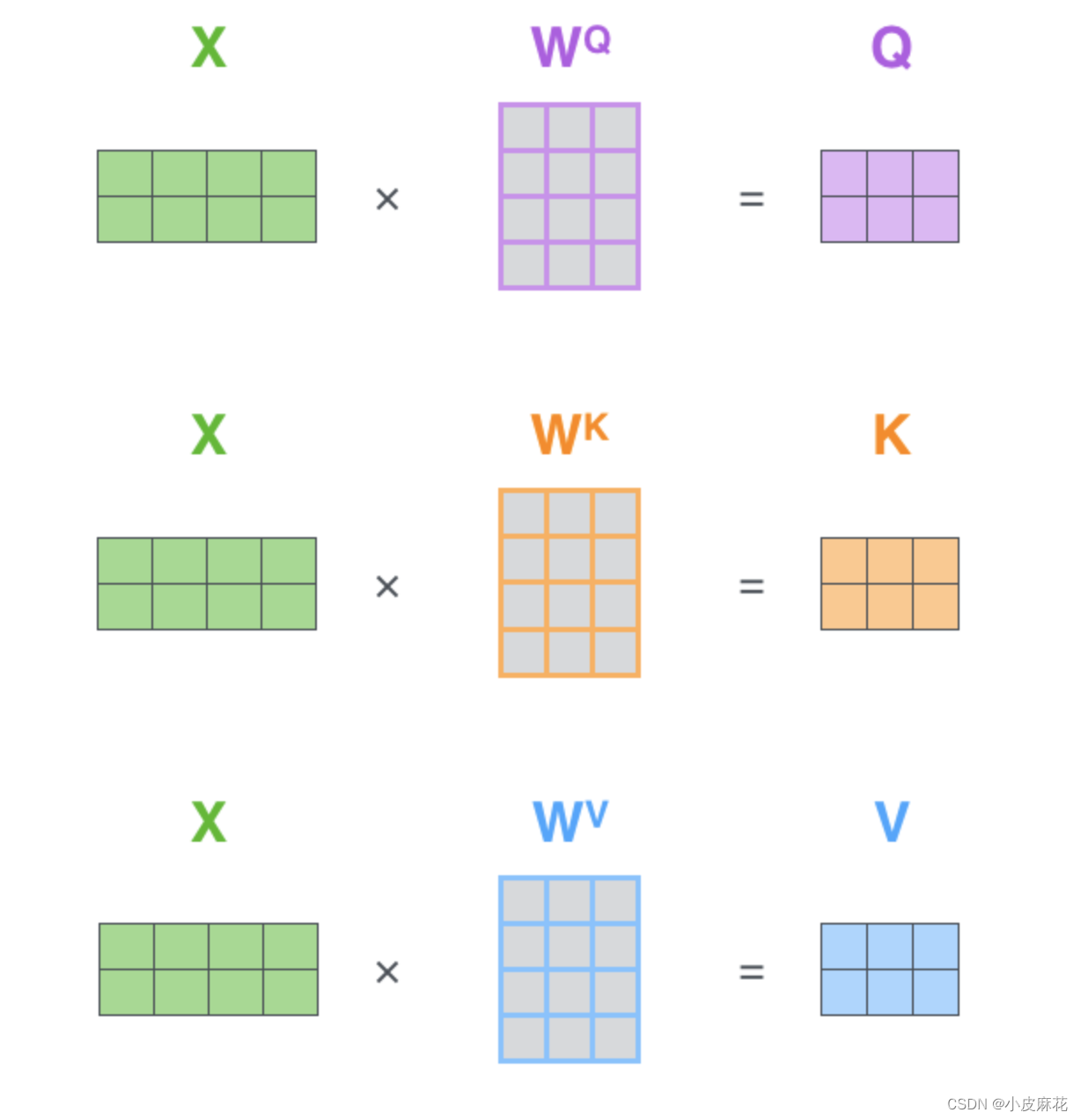
然后去计算attention,Q、K点乘得到初步的权重因子,并对Q、K点乘结果进行放缩,除以sqrt(dk),Q、K点乘之后的方差会随着维度的增大而增大,而大的方差会导致极小的梯度,为了防止梯度消失,所以除以sqrt(dk)来减小方差,最终再加一个softmax就得到了self attention的输出。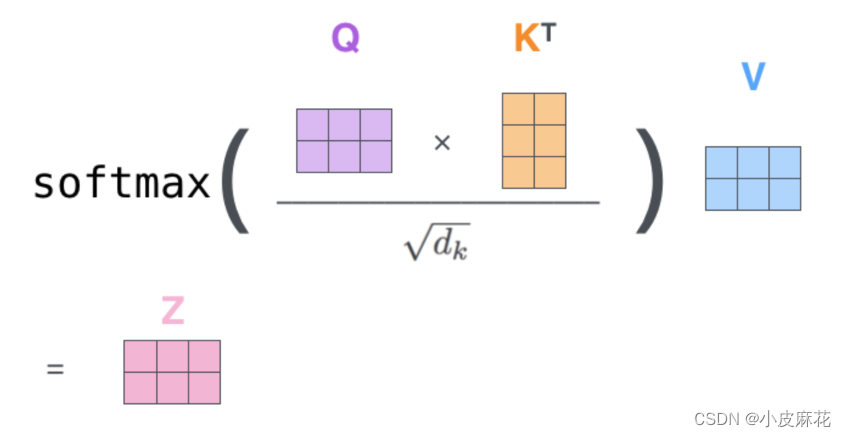
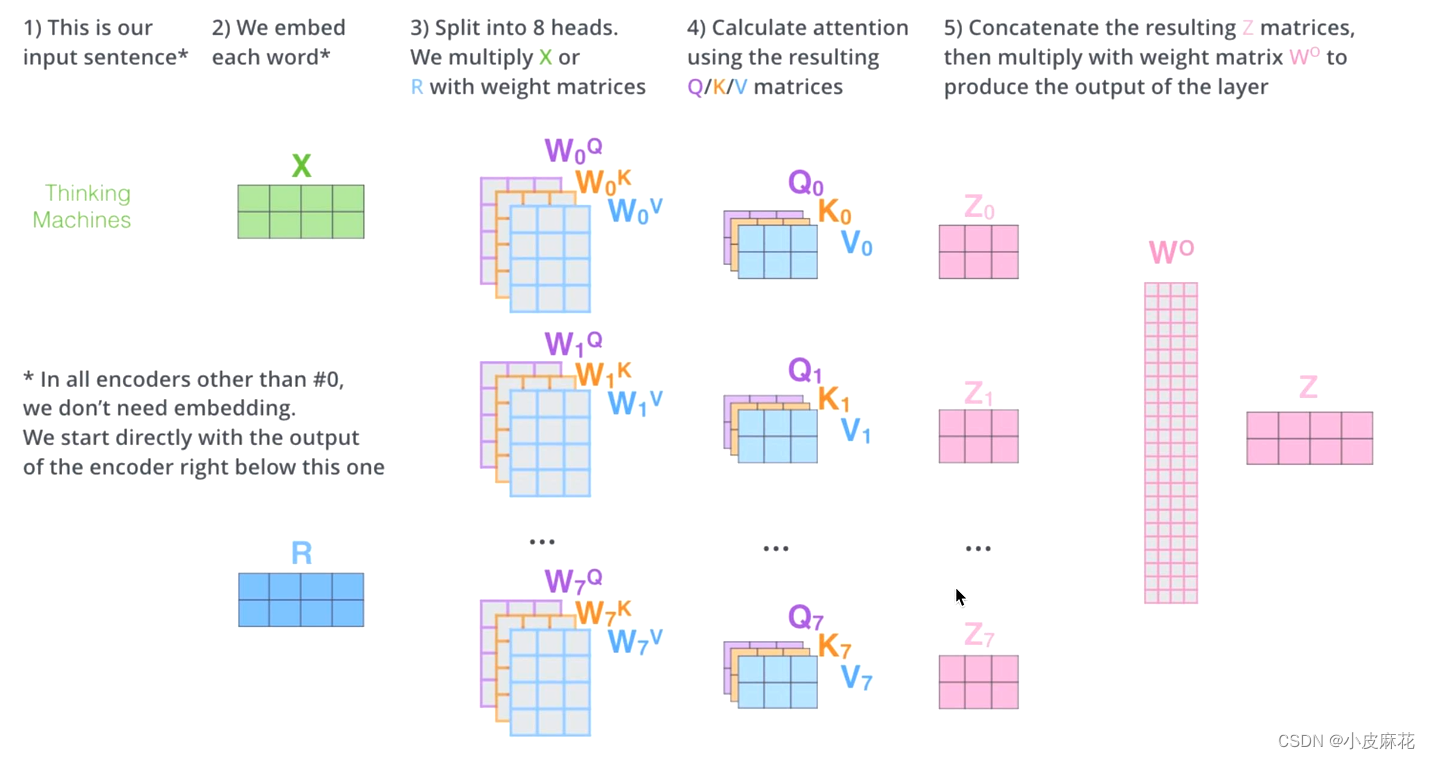
Multi–head-attention
Multi–head-attention使用了多个头进行运算,捕捉到了更多的信息,多头的数量用h表示,一般h=8,表示8个头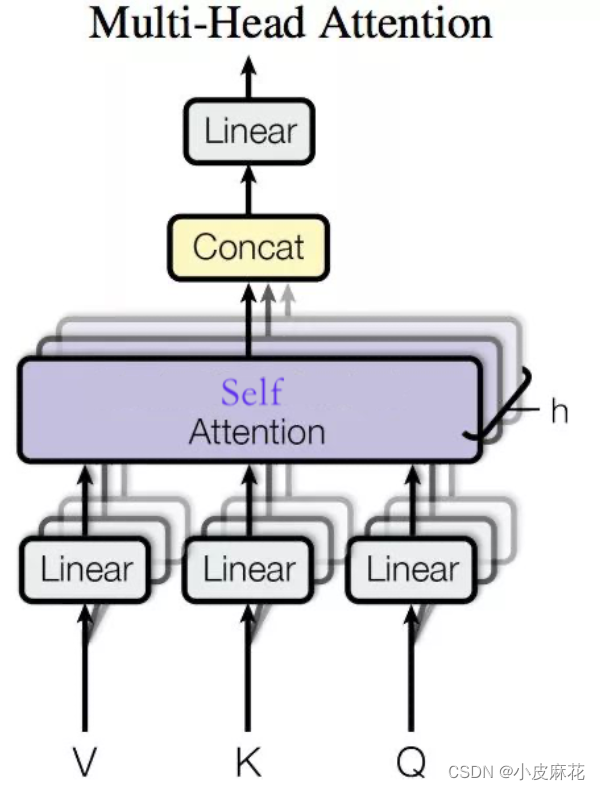
在输入每个self-attention之前,我们需将输入X均分的分到h个头中,得到Z1-Z7八个头的输出结果。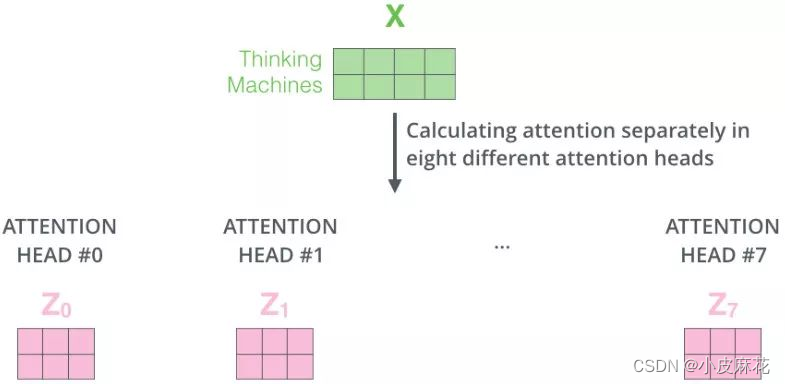
对于每个头计算相应的attention score,将其进行拼接,再与W0进行一个线性变换,就得到最终输出的Z。