其中pos表示token在sequence中的位置,d_model表示词嵌入的维度,i则是range(d_model)中的数值
首先来看一下Transformer结构的结构:
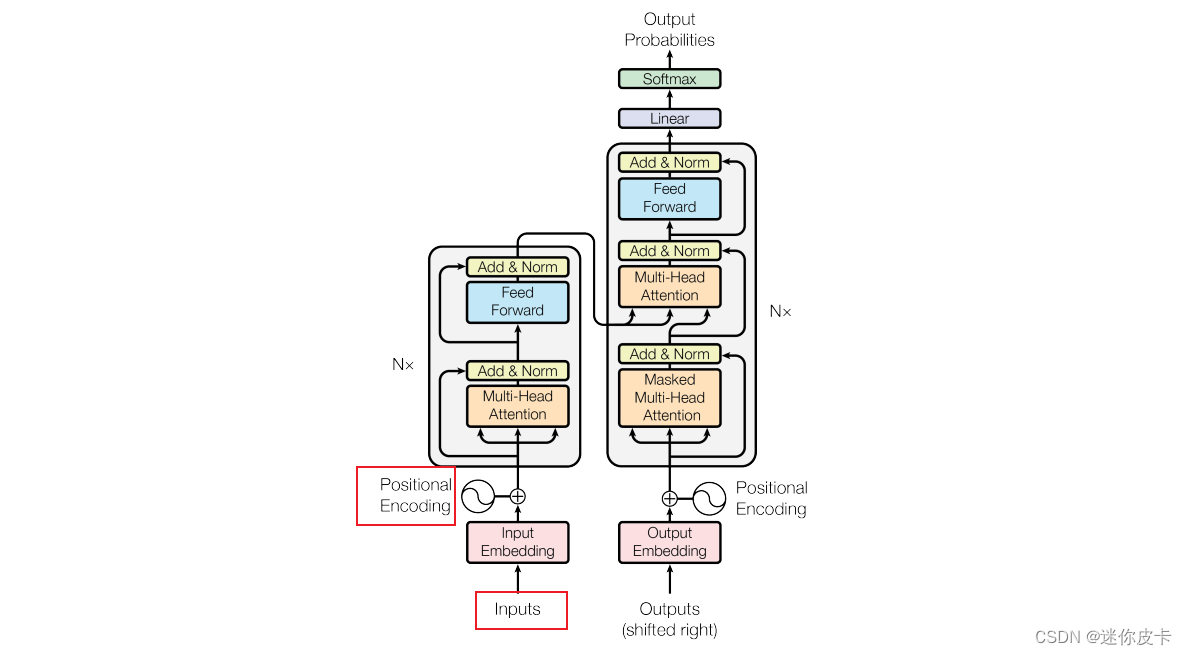
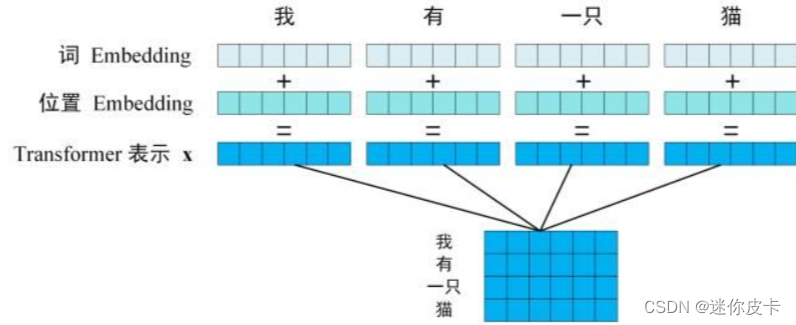
Transformer是由Encoder和Decoder两大部分组成,首先对于文本特征,需要进行Embedding,由于transformer抛弃了Rnn的结构,不能捕捉到序列的信息,交换单词位置,得到相应的attention也会发生交换,并不会发生数值上的改变,所以要对input进行Positional Encoding。
Positional encoding和input embedding是同等维度的,所以可以将两者进行相加,的到输入向量
接下来看一些Positional Encoding的计算公式:
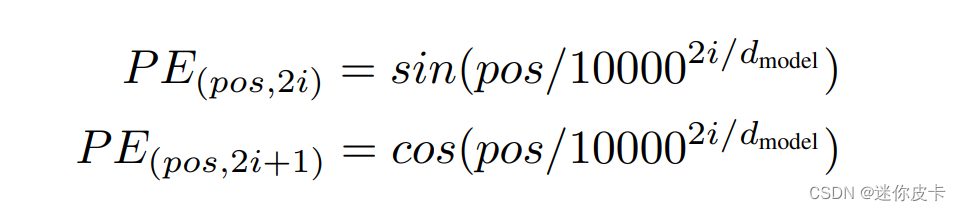
其中pos表示token在sequence中的位置,d_model表示词嵌入的维度,i则是range(d_model)中的数值,也就是说:对于单个token的d_model维度的词向量,奇数位置取cos,偶数位置取sin,最终的到一个维度和word embedding维度一样的矩阵,接下来可以看一下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
def get_positional_encoding(max_seq_len, embed_dim):
positional_encoding = np.array([
[pos / np.power(10000, 2 * i / embed_dim) for i in range(embed_dim)] if pos != 0 else np.zeros(embed_dim) for pos in range(max_seq_len)])
positional_encoding[1:, 0::2] = np.sin(positional_encoding[1:, 0::2])
positional_encoding[1:, 1::2] = np.cos(positional_encoding[1:, 1::2])
return positional_encoding
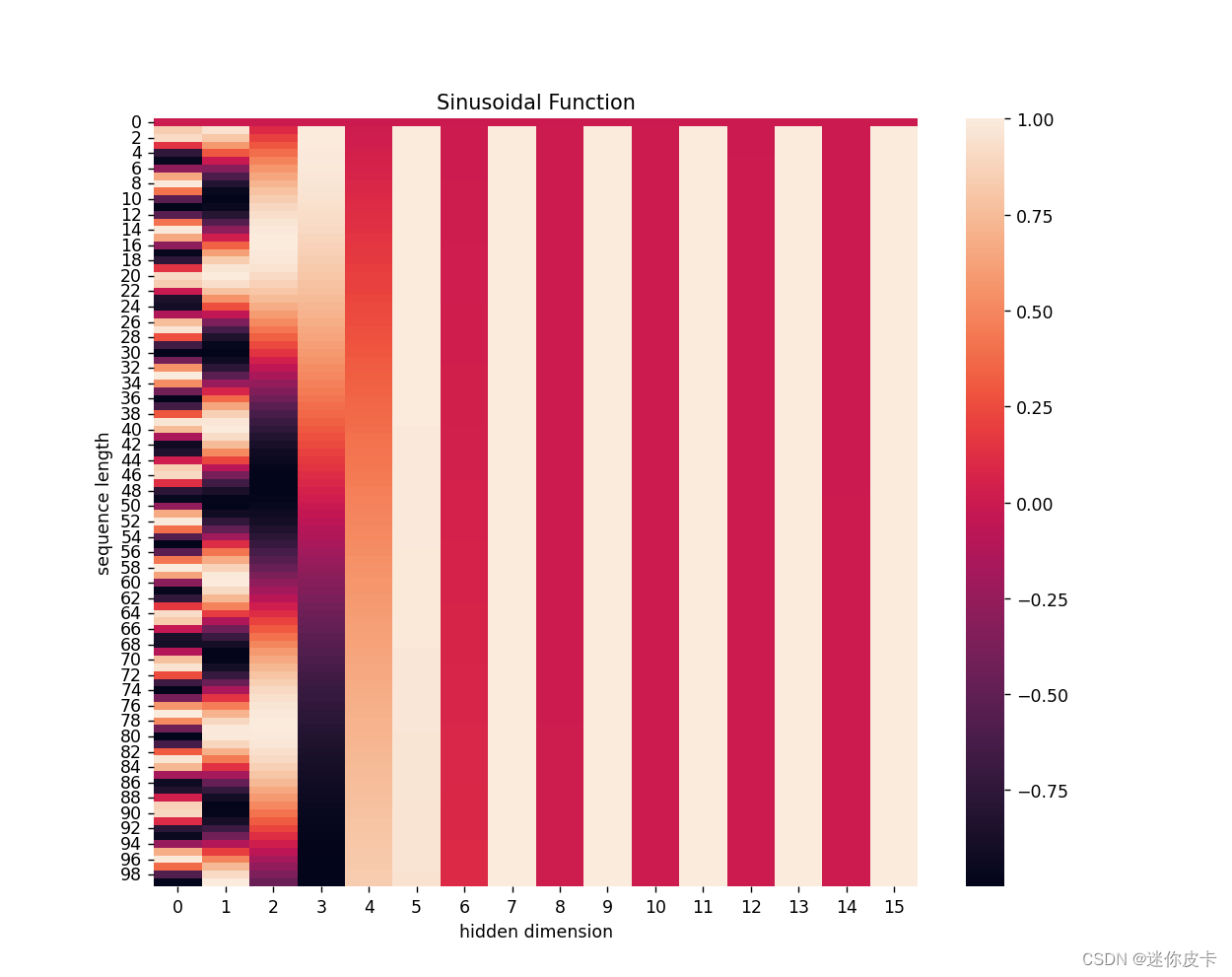
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
plt.figure(figsize=(10, 10))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")
plt.show()
|
首先求初始向量:positional_encoding,然后对其奇数列求sin,偶数列求cos:
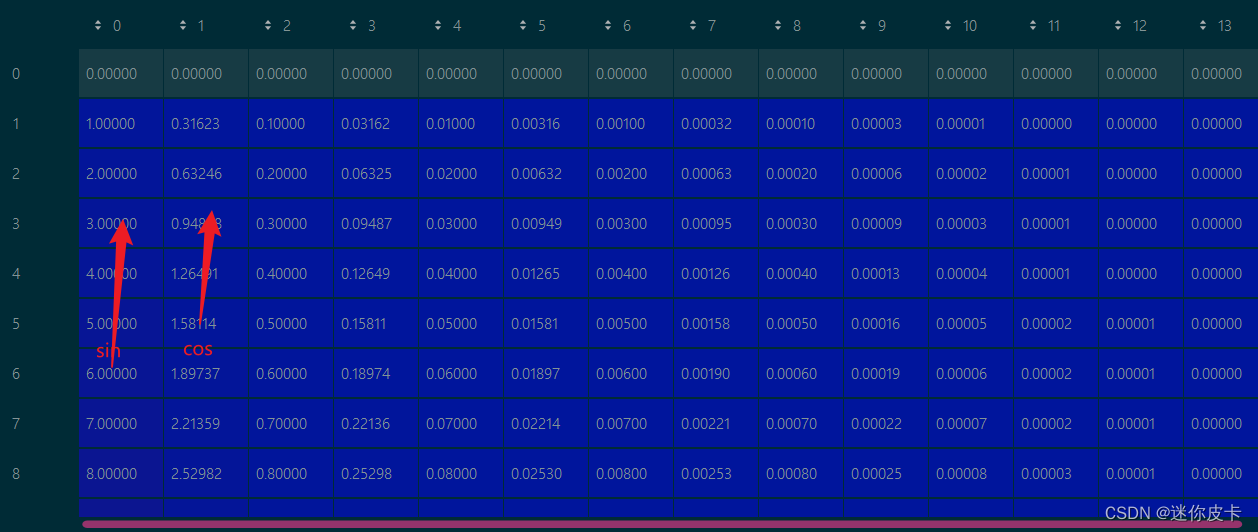
最终得到positional encoding之后的数据可视化: