CCF BDCI Web攻击检测与分类识别 Top8思路
CCF BDCI Web攻击检测与分类识别 Top8思路 赛题地址 :https://www.datafountain.cn/competitions/596
赛题背景: 某业务平台平均每月捕获到Web攻击数量超过2亿,涉及常见注入攻击,代码执行等类型。传统威胁检测手段通过分析已知攻击特征进行规则匹配,无法检测未知漏洞或攻击手法。如何快速准确地识别未知威胁攻击并且将不同攻击正确分类,对提升Web攻击检测能力至关重要。利用机器学习和深度学习技术对攻击报文进行识别和分类已经成为解决该问题的创新思路,有利于推动AI技术在威胁检测分析场景的研究与应用。
赛题任务: 参赛团队需要对前期提供的训练集进行分析,通过特征工程、机器学习和深度学习等方法构建AI模型,实现对每一条样本正确且快速分类,不断提高模型精确率和召回率。待模型优化稳定后,通过无标签测试集评估各参赛团队模型分类效果,以正确率评估各参赛团队模型质量。
决赛答辩: 决赛答辩中,评审专家将根据答辩作品的创新性、可用性等进行打分;最终成绩将综合考虑初赛成绩、创新性、可用性等方面确定最终排名,最终成绩 = 初赛复现成绩 * 80% + 决赛成绩 * 20%。
数据简介 赛题训练集分为6种不同标签,共计约3.5万条数据。训练数据集字段内容主要包括:
评测标准 评比期间将提供无标签测试集,参赛团队需提交对该测试集每条数据的模型分类结果,即每条数据中增加一个predict字段(模型分类结果),与训练集label字段含义保持一致。
标签
分类为正标签
分类为负标签
正标签
TP
FN
负标签
FP
TN
精确率计算公式:Precision = TP/(TP + FP)
代码如下 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import lightgbm as lgbimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom lightgbm import early_stoppingfrom lightgbm import log_evaluationfrom sklearn.decomposition import TruncatedSVDfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.metrics import accuracy_score,f1_scorefrom sklearn.model_selection import StratifiedKFoldfrom sklearn.preprocessing import LabelEncoderfrom tqdm import tqdmfrom user_agents import parsefrom sklearn.metrics import classification_reportfrom sklearn.metrics import confusion_matrixfrom catboost import CatBoostClassifierfrom xgboost import XGBClassifierfrom urllib.parse import quote, unquote, urlparseimport reimport glob pd.set_option('display.max_columns' , None )
1 2 3 4 5 6 7 8 9 10 11 def get_ua (row ): user_agent = parse(row['user_agent' ]) browser_family=str (user_agent.browser.family) os_family=str (user_agent.os.family) device_family=str (user_agent.device.family) device_brand=str (user_agent.device.brand) device_model=str (user_agent.device.model) return browser_family,os_family,device_family,device_brand,device_model
1 2 prob = np.load('E://data//DF//Web攻击检测与分类识别//large/deberta-v3-large_probs.npy' ) prob.shape
(4000, 6)
1 2 3 4 5 train=pd.read_pickle('E:\\data\\DF\\Web攻击检测与分类识别/large/oof_df.pkl' ) sub = pd.read_csv('E:\\data\\DF\\Web攻击检测与分类识别\\submit_example (10).csv' ) test=pd.read_csv('E:\\data\\DF\\Web攻击检测与分类识别/test.csv' ) train.head()
id
method
user_agent
url
refer
body
label
text
fold
0
1
2
3
4
5
0
13429
GET
'||(select 1 from (select pg_sleep(8))x)||'
/kelev/scripts/?C=M%3BO%3DA
NAN
GET /kelev/scripts/?C=M%3BO%3DA HTTP/1.1 Accep...
1
method:GET[SEP]user_agent:'||(select 1 from (s...
0
0.000238
0.999110
0.000445
0.000058
0.000040
0.000110
1
18125
GET
Dalvik/2.1.0 (Linux; U; Android 11; M2102K1C B...
/livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&adap...
NAN
GET /livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&...
1
method:GET[SEP]user_agent:Dalvik/2.1.0 (Linux;...
0
0.006598
0.992451
0.000763
0.000086
0.000067
0.000035
2
14538
GET
Dalvik/2.1.0 (Linux; U; Android 11; M2011K2C B...
/livemsg?ad_type=WL_WK&ty=web&pu=0&openudid=d2...
NAN
GET /livemsg?ad_type=WL_WK&ty=web&pu=0&openudi...
1
method:GET[SEP]user_agent:Dalvik/2.1.0 (Linux;...
0
0.000783
0.999017
0.000138
0.000031
0.000017
0.000013
3
7127
GET
Dalvik/2.1.0 (Linux; U; Android 10; MI 9 MIUI/...
/livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&adap...
NAN
NAN
1
method:GET[SEP]user_agent:Dalvik/2.1.0 (Linux;...
0
0.007603
0.991491
0.000725
0.000087
0.000062
0.000033
4
7
GET
Dalvik/2.1.0 (Linux; U; Android 10; ELS-AN00 B...
/livemsg?sdtfrom=v5004&ad_type=WL_WK&oadid=&ty...
NAN
GET /livemsg?sdtfrom=v5004&ad_type=WL_WK&oadid...
1
method:GET[SEP]user_agent:Dalvik/2.1.0 (Linux;...
0
0.000529
0.999257
0.000153
0.000020
0.000021
0.000019
id
method
user_agent
url
refer
body
0
0
GET
Mozilla/5.0 (Windows NT 10.0; Win64; x64) Appl...
/demo/aisec/upload.php?act='%7C%7C(select+1+fr...
http://demo.aisec.cn/demo/aisec/upload.php?t=0...
GET /demo/aisec/upload.php?act='%7C%7C(select+...
1
1
GET
Dalvik/2.1.0 (Linux; U; Android 11; M2102J2SC ...
/livemsg?ad_type=WL_WK&ty=web&pu=1&openudid=5f...
NaN
GET /livemsg?ad_type=WL_WK&ty=web&pu=1&openudi...
2
2
GET
Mozilla/5.0 (Windows NT 10.0; rv:78.0) Gecko/2...
/create_user/?username=%3Cscript%3Ealert(docum...
NaN
NaN
3
3
GET
NaN
/mmsns/WeDwicXmkOl4kjKsBycicI0H3q41r6syFFvu46h...
NaN
NaN
4
4
PUT
Mozilla/5.0 (Windows NT 10.0; rv:78.0) Gecko/2...
/naizau.jsp/
NaN
GET /login HTTP/1.1 Host: 111.160.211.18:8088 ...
id 0
method 0
user_agent 0
url 0
refer 0
body 0
label 0
text 0
fold 0
0 0
1 0
2 0
3 0
4 0
5 0
dtype: int64
Index(['id', 'method', 'user_agent', 'url', 'refer', 'body', 'label', 'text',
'fold', '0', '1', '2', '3', '4', '5'],
dtype='object')
1 2 test[['0' , '1' , '2' , '3' , '4' , '5' ]]=prob
1 2 3 train=train.drop('text' ,axis=1 ) train=train.drop('fold' ,axis=1 )
1 2 train=train[['id' , 'method' , 'user_agent' , 'url' , 'refer' , 'body' , '0' , '1' , '2' , '3' , '4' , '5' , 'label' ]]
1 2 print ("train.shape" ,train.shape)print ("test.shape" ,test.shape)
train.shape (33037, 13)
test.shape (4000, 12)
数据分析 赛题训练集分为6种不同标签,共计约3.5万条数据。训练数据集字段内容主要包括:
Index(['id', 'method', 'user_agent', 'url', 'refer', 'body', '0', '1', '2',
'3', '4', '5', 'label'],
dtype='object')
‘lable’看着很别扭,重新rename一下
1 train=train.rename(columns={'lable' :'label' })
id int64
method object
user_agent object
url object
refer object
body object
0 float32
1 float32
2 float32
3 float32
4 float32
5 float32
label int64
dtype: object
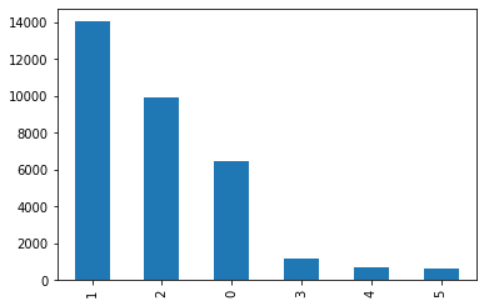
1 2 train['label' ].value_counts()
1 14038
2 9939
0 6489
3 1215
4 697
5 659
Name: label, dtype: int64
1 2 train['label' ].value_counts().plot(kind='bar' ) plt.show()
1 2 data=pd.concat([train,test],axis=0 ).reset_index(drop=True ) data.nunique()
id 19497
method 21
user_agent 1087
url 36613
refer 941
body 22380
0 35915
1 31618
2 36061
3 36961
4 36965
5 36959
label 6
dtype: int64
1 2 3 4 5 data['user_agent' ]=data['user_agent' ].fillna('NAN' ) data['refer' ]=data['refer' ].fillna('NAN' ) data['body' ]=data['body' ].fillna('NAN' ) data['url' ]=data['url' ].fillna('NAN' )
1 2 3 4 ua_cols=['browser_family' , 'os_family' , 'device_family' ,'device_brand' ,'device_model' ] data[ua_cols] = data.apply(get_ua, axis=1 , result_type="expand" ) data.head()
id
method
user_agent
url
refer
body
0
1
2
3
4
5
label
browser_family
os_family
device_family
device_brand
device_model
0
13429
GET
'||(select 1 from (select pg_sleep(8))x)||'
/kelev/scripts/?C=M%3BO%3DA
NAN
GET /kelev/scripts/?C=M%3BO%3DA HTTP/1.1 Accep...
0.000238
0.999110
0.000445
0.000058
0.000040
0.000110
1.0
Other
Other
Other
None
None
1
18125
GET
Dalvik/2.1.0 (Linux; U; Android 11; M2102K1C B...
/livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&adap...
NAN
GET /livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&...
0.006598
0.992451
0.000763
0.000086
0.000067
0.000035
1.0
Android
Android
M2102K1C
Generic_Android
M2102K1C
2
14538
GET
Dalvik/2.1.0 (Linux; U; Android 11; M2011K2C B...
/livemsg?ad_type=WL_WK&ty=web&pu=0&openudid=d2...
NAN
GET /livemsg?ad_type=WL_WK&ty=web&pu=0&openudi...
0.000783
0.999017
0.000138
0.000031
0.000017
0.000013
1.0
Android
Android
M2011K2C
Generic_Android
M2011K2C
3
7127
GET
Dalvik/2.1.0 (Linux; U; Android 10; MI 9 MIUI/...
/livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&adap...
NAN
NAN
0.007603
0.991491
0.000725
0.000087
0.000062
0.000033
1.0
Android
Android
XiaoMi MI 9
XiaoMi
MI 9
4
7
GET
Dalvik/2.1.0 (Linux; U; Android 10; ELS-AN00 B...
/livemsg?sdtfrom=v5004&ad_type=WL_WK&oadid=&ty...
NAN
GET /livemsg?sdtfrom=v5004&ad_type=WL_WK&oadid...
0.000529
0.999257
0.000153
0.000020
0.000021
0.000019
1.0
Android
Android
ELS-AN00
Huawei
ELS-AN00
基础特征 1 2 import urllib.parseimport urllib
1 2 3 4 5 6 data['user_agent_len' ]=data['user_agent' ].apply(lambda x:len (x)) data['url_len' ]=data['url' ].apply(lambda x:len (x)) data['refer_len' ]=data['refer' ].apply(lambda x:len (x)) data['body_len' ]=data['body' ].apply(lambda x:len (x)) data['body_user_agent_len_diff' ]=data['body_len' ]-data['user_agent_len' ] data['body_url_len_diff' ]=data['body_len' ]-data['url_len' ]
1 2 3 4 5 6 7 8 9 10 11 12 texts=data['user_agent' ].values.tolist() n_components = 16 tf = TfidfVectorizer(min_df= 1 , max_df=0.5 ,analyzer = 'char_wb' , ngram_range = (1 ,3 )) X = tf.fit_transform(texts) svd = TruncatedSVD(n_components=n_components, random_state=42 ) X_svd = svd.fit_transform(X) df_tfidf = pd.DataFrame(X_svd) df_tfidf.columns = [f'user_agent_name_tfidf_{i} ' for i in range (n_components)] data=pd.concat([data,df_tfidf],axis=1 )
1 2 3 4 5 6 7 8 9 10 11 texts=data['url' ].values.tolist() n_components = 16 tf = TfidfVectorizer(min_df= 1 , max_df=0.5 ,analyzer = 'char_wb' , ngram_range = (1 ,3 )) X = tf.fit_transform(texts) svd = TruncatedSVD(n_components=n_components, random_state=42 ) X_svd = svd.fit_transform(X) df_tfidf = pd.DataFrame(X_svd) df_tfidf.columns = [f'url_name_tfidf_{i} ' for i in range (n_components)] data=pd.concat([data,df_tfidf],axis=1 )
1 2 3 4 5 6 7 8 9 10 11 texts=data['body' ].values.tolist() n_components = 32 tf = TfidfVectorizer(min_df= 1 , max_df=0.5 ,analyzer = 'char_wb' , ngram_range = (1 ,3 )) X = tf.fit_transform(texts) svd = TruncatedSVD(n_components=n_components, random_state=42 ) X_svd = svd.fit_transform(X) df_tfidf = pd.DataFrame(X_svd) df_tfidf.columns = [f'body_tfidf_{i} ' for i in range (n_components)] data=pd.concat([data,df_tfidf],axis=1 )
1 2 3 for f in ['method' , 'url' ,'refer' , 'body' ,'browser_family' ,'os_family' ,'device_family' ,'device_brand' ,'device_model' ]: data[f'id_{f} _nunique' ] = data.groupby(['id' ])[f].transform('nunique' ) data[f'id_{f} _count' ] = data.groupby(['id' ])[f].transform('count' )
1 re.split('[=&]' , urlparse(data['url' ][0 ])[4 ])
['C', 'M%3BO%3DA']
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def get_url_query (s ): li = re.split('[=&]' , urlparse(s)[4 ]) return [li[i] for i in range (len (li)) if i % 2 == 1 ] def find_max_str_length (x ): max_ = 0 li = [len (i) for i in x] return max (li) if len (li) > 0 else 0 def find_str_length_std (x ): max_ = 0 li = [len (i) for i in x] return np.std(li) if len (li) > 0 else -1 data['url_unquote' ] = data['url' ].apply(unquote) data['url_query' ] = data['url_unquote' ].apply(lambda x: get_url_query(x)) data['url_query_num' ] = data['url_query' ].apply(len ) data['url_query_max_len' ] = data['url_query' ].apply(find_max_str_length) data['url_query_len_std' ] = data['url_query' ].apply(find_str_length_std) data['url' ].apply(unquote)
0 /kelev/scripts/?C=M;O=A
1 /livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&adap...
2 /livemsg?ad_type=WL_WK&ty=web&pu=0&openudid=d2...
3 /livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&adap...
4 /livemsg?sdtfrom=v5004&ad_type=WL_WK&oadid=&ty...
...
37032 /livemsg?ad_type=WL_WK&ty=web&pu=1&openudid=64...
37033 /runtime.js
37034 /query?493521812
37035 /stats.php?rand=JtmT4wBtrpNy5RJnNX9wCUo
37036 /api/gateway.do?method=qihoo.sdk.user.mobile.l...
Name: url, Length: 37037, dtype: object
id
method
user_agent
url
refer
body
0
1
2
3
4
5
label
browser_family
os_family
device_family
device_brand
device_model
user_agent_len
url_len
refer_len
body_len
body_user_agent_len_diff
body_url_len_diff
user_agent_name_tfidf_0
user_agent_name_tfidf_1
user_agent_name_tfidf_2
user_agent_name_tfidf_3
user_agent_name_tfidf_4
user_agent_name_tfidf_5
user_agent_name_tfidf_6
user_agent_name_tfidf_7
user_agent_name_tfidf_8
user_agent_name_tfidf_9
user_agent_name_tfidf_10
user_agent_name_tfidf_11
user_agent_name_tfidf_12
user_agent_name_tfidf_13
user_agent_name_tfidf_14
user_agent_name_tfidf_15
url_name_tfidf_0
url_name_tfidf_1
url_name_tfidf_2
url_name_tfidf_3
url_name_tfidf_4
url_name_tfidf_5
url_name_tfidf_6
url_name_tfidf_7
url_name_tfidf_8
url_name_tfidf_9
url_name_tfidf_10
url_name_tfidf_11
url_name_tfidf_12
url_name_tfidf_13
url_name_tfidf_14
url_name_tfidf_15
body_tfidf_0
body_tfidf_1
body_tfidf_2
body_tfidf_3
body_tfidf_4
body_tfidf_5
body_tfidf_6
body_tfidf_7
body_tfidf_8
body_tfidf_9
body_tfidf_10
body_tfidf_11
body_tfidf_12
body_tfidf_13
body_tfidf_14
body_tfidf_15
body_tfidf_16
body_tfidf_17
body_tfidf_18
body_tfidf_19
body_tfidf_20
body_tfidf_21
body_tfidf_22
body_tfidf_23
body_tfidf_24
body_tfidf_25
body_tfidf_26
body_tfidf_27
body_tfidf_28
body_tfidf_29
body_tfidf_30
body_tfidf_31
id_method_nunique
id_method_count
id_url_nunique
id_url_count
id_refer_nunique
id_refer_count
id_body_nunique
id_body_count
id_browser_family_nunique
id_browser_family_count
id_os_family_nunique
id_os_family_count
id_device_family_nunique
id_device_family_count
id_device_brand_nunique
id_device_brand_count
id_device_model_nunique
id_device_model_count
url_unquote
url_query
url_query_num
url_query_max_len
url_query_len_std
0
13429
GET
'||(select 1 from (select pg_sleep(8))x)||'
/kelev/scripts/?C=M%3BO%3DA
NAN
GET /kelev/scripts/?C=M%3BO%3DA HTTP/1.1 Accep...
0.000238
0.999110
0.000445
0.000058
0.000040
0.000110
1.0
Other
Other
Other
None
None
43
27
3
212
169
185
0.010070
0.009456
0.001205
0.003217
0.021082
0.000999
-0.000847
-0.002107
0.008443
0.002747
0.023997
-0.003526
-0.001894
-0.013000
-0.005918
0.009153
0.066298
0.059683
-0.057310
-0.006595
-0.001159
0.094755
-0.021858
0.023071
-0.001968
0.043890
0.022147
-0.006037
-0.005375
0.014239
0.077494
0.081818
0.000054
0.115960
0.105404
-0.027789
-0.002577
0.064009
-0.039324
0.006577
0.023000
-0.064038
0.021134
-0.058787
0.011353
0.066560
0.010658
0.189591
-0.067039
-0.116538
-0.014128
-0.029329
0.047018
-0.023777
-0.035825
0.005829
0.013030
-0.022777
-0.007482
0.039357
0.046385
-0.007902
-0.029089
-0.051989
1
2
2
2
1
2
2
2
2
2
2
2
1
2
1
2
1
2
/kelev/scripts/?C=M;O=A
[M;O]
1
3
0.000000
1
18125
GET
Dalvik/2.1.0 (Linux; U; Android 11; M2102K1C B...
/livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&adap...
NAN
GET /livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&...
0.006598
0.992451
0.000763
0.000086
0.000067
0.000035
1.0
Android
Android
M2102K1C
Generic_Android
M2102K1C
67
1747
3
2016
1949
269
0.035096
0.120188
0.270092
0.655747
-0.042591
-0.024738
-0.019824
-0.000642
-0.015951
-0.183311
-0.026321
-0.061993
-0.018288
0.027496
-0.012776
-0.002250
0.617250
-0.130247
0.079094
-0.023195
0.003702
-0.030486
-0.013201
-0.021136
0.012303
-0.006278
-0.023727
-0.003599
0.027036
0.006405
-0.005268
0.010234
0.000132
0.530101
-0.277845
0.022171
-0.069403
-0.062703
-0.006813
0.001156
-0.028995
-0.009364
-0.013567
0.015499
-0.009968
-0.032960
-0.000036
-0.008127
-0.000813
0.001447
0.009261
-0.017541
-0.000682
-0.003697
0.007340
-0.010968
0.008710
-0.067023
-0.014870
-0.024112
0.011792
0.004538
0.014397
-0.003550
1
2
2
2
1
2
2
2
2
2
2
2
2
2
2
2
2
2
/livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&adap...
[WL_WK, , web, 0, 1, 210810, 116, 1, 8, fa0d30...
23
1324
268.709026
2
14538
GET
Dalvik/2.1.0 (Linux; U; Android 11; M2011K2C B...
/livemsg?ad_type=WL_WK&ty=web&pu=0&openudid=d2...
NAN
GET /livemsg?ad_type=WL_WK&ty=web&pu=0&openudi...
0.000783
0.999017
0.000138
0.000031
0.000017
0.000013
1.0
Android
Android
M2011K2C
Generic_Android
M2011K2C
67
1688
3
1986
1919
298
0.034866
0.170330
0.292857
0.713273
-0.047369
-0.025480
-0.014846
-0.002015
-0.095211
-0.199969
0.001352
0.004859
0.026900
-0.000053
-0.045812
-0.003042
0.662307
-0.134895
0.074788
-0.033836
0.004867
-0.012766
-0.014195
-0.019396
0.016613
-0.006143
-0.018700
-0.012640
0.030395
0.004169
-0.005899
0.005060
0.000137
0.557311
-0.298627
0.021799
-0.072395
-0.035369
-0.009561
-0.020158
-0.030540
-0.019107
-0.011824
0.016220
-0.010370
-0.021592
0.002470
0.001666
-0.004027
-0.000666
0.012006
-0.009133
-0.007882
-0.001795
-0.003188
-0.015516
0.010797
-0.083144
-0.021120
-0.029922
0.020777
0.001687
0.006579
-0.001808
1
2
2
2
1
2
2
2
2
2
2
2
2
2
2
2
2
2
/livemsg?ad_type=WL_WK&ty=web&pu=0&openudid=d2...
[WL_WK, web, 0, d24c93f6c8de719a00f1676f3a9a53...
29
1154
209.374211
3
7127
GET
Dalvik/2.1.0 (Linux; U; Android 10; MI 9 MIUI/...
/livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&adap...
NAN
NAN
0.007603
0.991491
0.000725
0.000087
0.000062
0.000033
1.0
Android
Android
XiaoMi MI 9
XiaoMi
MI 9
64
1613
3
3
-61
-1610
0.038503
0.058521
0.184916
0.434441
0.026507
-0.024867
-0.016191
0.021308
0.058906
0.048677
-0.015773
-0.017188
0.012508
0.026593
0.009872
0.001220
0.621003
-0.119104
0.071898
-0.014246
-0.005748
-0.025066
-0.015300
-0.006643
0.011277
-0.011099
-0.026949
-0.013011
0.027294
0.006678
0.006156
0.004784
1.000000
-0.000356
-0.000224
-0.000019
0.000078
0.000016
-0.000132
-0.000012
-0.000029
0.000011
-0.000044
-0.000041
-0.000041
0.000027
-0.000017
-0.000027
-0.000017
-0.000096
0.000005
0.000026
0.000013
0.000016
-0.000005
-0.000005
0.000015
-0.000004
0.000011
0.000021
-0.000004
0.000045
0.000019
-0.000019
1
3
3
3
1
3
2
3
2
3
2
3
3
3
2
3
3
3
/livemsg?ad_type=WL_WK&oadid=&ty=web&pu=0&adap...
[WL_WK, , web, 0, 1, 201209, 116, 1, 8, bbe035...
24
1186
235.820461
4
7
GET
Dalvik/2.1.0 (Linux; U; Android 10; ELS-AN00 B...
/livemsg?sdtfrom=v5004&ad_type=WL_WK&oadid=&ty...
NAN
GET /livemsg?sdtfrom=v5004&ad_type=WL_WK&oadid...
0.000529
0.999257
0.000153
0.000020
0.000021
0.000019
1.0
Android
Android
ELS-AN00
Huawei
ELS-AN00
66
1467
3
1704
1638
237
0.023016
0.076053
0.211935
0.431614
-0.013015
-0.028123
0.016032
-0.039645
0.129501
0.388460
-0.012173
-0.016553
-0.012854
-0.049835
-0.037182
-0.024569
0.615644
-0.116622
0.066164
-0.019455
-0.007366
-0.022974
-0.016564
-0.006819
-0.000959
-0.011903
-0.022060
-0.011351
0.002437
-0.008505
-0.008668
-0.004333
0.000129
0.535128
-0.294560
0.024614
-0.084538
-0.049889
-0.019040
-0.000086
-0.029467
-0.026259
-0.010166
0.009809
-0.017834
-0.018439
0.007596
-0.017013
-0.005269
0.002957
0.006733
-0.010658
-0.006394
-0.005429
0.011300
-0.024379
0.006489
-0.061012
-0.019155
-0.021446
0.021441
-0.001876
0.002968
-0.005974
2
5
5
5
3
5
5
5
3
5
3
5
3
5
3
5
3
5
/livemsg?sdtfrom=v5004&ad_type=WL_WK&oadid=&ty...
[v5004, WL_WK, , web, 0, 20220209V0BT5X00, 1, ...
27
972
182.378599
1 2 3 4 5 6 7 8 9 10 11 12 13 def find_url_filetype (x ): try : return re.search(r'\.[a-z]+' , x).group() except : return '__NaN__' data['url_path' ] = data['url_unquote' ].apply(lambda x: urlparse(x)[2 ]) data['url_filetype' ] = data['url_path' ].apply(lambda x: find_url_filetype(x)) data['url_path_len' ] = data['url_path' ].apply(len ) data['url_path_num' ] = data['url_path' ].apply(lambda x: len (re.findall('/' , x)))
1 2 data['ua_short' ] = data['user_agent' ].apply(lambda x: x.split('/' )[0 ]) data['ua_first' ] = data['user_agent' ].apply(lambda x: x.split(' ' )[0 ])
1 2 3 for col in tqdm(['method' , 'refer' , 'browser_family' ,'os_family' ,'device_family' , 'device_brand' , 'device_model' ,'url_filetype' ,'ua_short' ,'ua_first' ]): le = LabelEncoder() data[col] = le.fit_transform(data[col])
100%|██████████████████████████████████████████████████████████████████████████████████| 10/10 [00:00<00:00, 82.97it/s]
1 len (data.select_dtypes(include=['int' ,'float' ]).columns.tolist())
109
1 2 3 col = data.select_dtypes(include=['int' ,'float' ]).columns.tolist() data = data[col] feature_names = [i for i in col if i not in ['id' ,'label' ]]
1 2 3 4 5 6 7 train = data[data['label' ].notnull()].reset_index(drop = True ) test = data[~data['label' ].notnull()].reset_index(drop = True ) x_train = train[feature_names] y_train = train['label' ] x_test = test[feature_names]
(33037, 107)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 def lgb_model (train, target, test, k ): feats = [f for f in train.columns if f not in ['id' ,'label' , 'url' , 'url_count' ]] print ('Current num of features:' , len (feats)) oof_probs = np.zeros((train.shape[0 ],6 )) output_preds = 0 offline_score = [] feature_importance_df = pd.DataFrame() parameters = { 'learning_rate' : 0.03 , 'boosting_type' : 'gbdt' , 'objective' : 'multiclass' , 'metric' : 'multi_error' , 'num_class' : 6 , 'num_leaves' : 31 , 'feature_fraction' : 0.6 , 'bagging_fraction' : 0.8 , 'min_data_in_leaf' : 15 , 'verbose' : -1 , 'nthread' : -1 , 'max_depth' : 7 } seeds = [2020 ] for seed in seeds: folds = StratifiedKFold(n_splits=k, shuffle=True , random_state=seed) for i, (train_index, test_index) in enumerate (folds.split(train, target)): train_y, test_y = target.iloc[train_index], target.iloc[test_index] train_X, test_X = train[feats].iloc[train_index, :], train[feats].iloc[test_index, :] dtrain = lgb.Dataset(train_X, label=train_y) dval = lgb.Dataset(test_X, label=test_y) lgb_model = lgb.train( parameters, dtrain, num_boost_round=8000 , valid_sets=[dval], callbacks=[early_stopping(100 ), log_evaluation(100 )], ) oof_probs[test_index] = lgb_model.predict(test_X[feats], num_iteration=lgb_model.best_iteration) / len ( seeds) offline_score.append(lgb_model.best_score['valid_0' ]['multi_error' ]) output_preds += lgb_model.predict(test[feats], num_iteration=lgb_model.best_iteration) / folds.n_splits / len (seeds) print (offline_score) fold_importance_df = pd.DataFrame() fold_importance_df["feature" ] = feats fold_importance_df["importance" ] = lgb_model.feature_importance(importance_type='gain' ) fold_importance_df["fold" ] = i + 1 feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0 ) print ('OOF-MEAN-AUC:%.6f, OOF-STD-AUC:%.6f' % (np.mean(offline_score), np.std(offline_score))) print ('feature importance:' ) print (feature_importance_df.groupby(['feature' ])['importance' ].mean().sort_values(ascending=False ).head(50 )) return output_preds, oof_probs, np.mean(offline_score), feature_importance_df
1 2 3 4 5 print ('开始模型训练train' )lgb_preds, lgb_oof, lgb_score, feature_importance_df = lgb_model(train=train[feature_names], target=train['label' ], test=test[feature_names], k=5 )
开始模型训练train
Current num of features: 107
Training until validation scores don't improve for 100 rounds
[100] valid_0's multi_error: 0.0145278
[200] valid_0's multi_error: 0.0136199
[300] valid_0's multi_error: 0.0134685
Early stopping, best iteration is:
[203] valid_0's multi_error: 0.0133172
[0.013317191283292978]
Training until validation scores don't improve for 100 rounds
[100] valid_0's multi_error: 0.0119552
Early stopping, best iteration is:
[63] valid_0's multi_error: 0.0116525
[0.013317191283292978, 0.011652542372881356]
Training until validation scores don't improve for 100 rounds
[100] valid_0's multi_error: 0.011503
Early stopping, best iteration is:
[92] valid_0's multi_error: 0.011503
[0.013317191283292978, 0.011652542372881356, 0.011502951415165732]
Training until validation scores don't improve for 100 rounds
[100] valid_0's multi_error: 0.011503
Early stopping, best iteration is:
[55] valid_0's multi_error: 0.0107462
[0.013317191283292978, 0.011652542372881356, 0.011502951415165732, 0.010746178295746934]
Training until validation scores don't improve for 100 rounds
[100] valid_0's multi_error: 0.011503
Early stopping, best iteration is:
[21] valid_0's multi_error: 0.0112002
[0.013317191283292978, 0.011652542372881356, 0.011502951415165732, 0.010746178295746934, 0.011200242167398214]
OOF-MEAN-AUC:0.011684, OOF-STD-AUC:0.000873
feature importance:
feature
2 222576.439984
1 211736.666876
0 147032.174178
4 108800.598945
3 86021.756831
browser_family 62270.501839
5 39814.736140
body_tfidf_0 27317.752312
body_tfidf_1 23303.336642
url_name_tfidf_2 16427.787706
url_name_tfidf_14 15618.236285
url_name_tfidf_3 14344.577968
user_agent_len 9418.270741
body_user_agent_len_diff 9103.063841
user_agent_name_tfidf_2 8463.647873
url_query_max_len 6510.758108
user_agent_name_tfidf_5 4018.171339
body_tfidf_3 3672.676081
body_tfidf_23 3355.861338
user_agent_name_tfidf_4 3142.178290
url_name_tfidf_4 3127.492671
url_name_tfidf_13 2886.949569
url_name_tfidf_1 2849.448233
url_name_tfidf_5 2676.723486
user_agent_name_tfidf_7 2330.854639
user_agent_name_tfidf_14 2310.199494
refer_len 2145.159362
user_agent_name_tfidf_3 2103.610035
body_tfidf_10 1986.768004
url_name_tfidf_6 1866.483835
body_url_len_diff 1849.085455
body_tfidf_6 1846.585181
body_len 1821.060478
user_agent_name_tfidf_0 1743.131918
id_method_count 1659.460621
user_agent_name_tfidf_13 1627.554725
body_tfidf_5 1539.584926
url_name_tfidf_8 1485.817275
url_name_tfidf_9 1449.335372
url_name_tfidf_12 1429.778973
url_name_tfidf_10 1413.196746
url_name_tfidf_11 1296.268733
user_agent_name_tfidf_9 1290.671890
url_len 1284.274063
body_tfidf_12 1279.712368
body_tfidf_9 1209.730761
body_tfidf_8 1161.935181
url_name_tfidf_15 1158.114828
url_name_tfidf_7 998.550187
url_name_tfidf_0 998.193206
Name: importance, dtype: float64
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58
1 sub['predict' ]=np.argmax(lgb_preds,axis=1 )
1 sub['predict' ].value_counts()
2 855
1 828
0 804
3 666
4 447
5 400
Name: predict, dtype: int64
1 accuracy_score(train['label' ],np.argmax(lgb_oof,axis=1 ))
0.9883161303992494
1 2 3 4 5 6 7 8 f1_score(np.argmax(lgb_oof,axis=1 ),train['label' ],average= 'macro' )
0.9650199644033531
1 print (classification_report(train['label' ],np.argmax(lgb_oof,axis=1 )))
precision recall f1-score support
0.0 0.99 1.00 1.00 6489
1.0 0.99 0.99 0.99 14038
2.0 0.99 0.99 0.99 9939
3.0 0.94 0.93 0.94 1215
4.0 0.94 0.87 0.90 697
5.0 0.97 0.98 0.98 659
accuracy 0.99 33037
macro avg 0.97 0.96 0.97 33037
weighted avg 0.99 0.99 0.99 33037