textrank:将待抽取关键词的文本进行分词,以固定窗口大小,词之间的共现关系,构建图
基于jieba 关键字提取的方法
1,将待抽取关键词的文本进行分词
2,以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
3,计算图中节点的PageRank,注意是无向带权图
·关键字的提取代码:
1
2
3
4
5
|
def testRank(corpus1, corpus2):
keywords_textrank1 = jieba.analyse.textrank(corpus1, 15)
keywords_textrank2 = jieba.analyse.textrank(corpus2, 15)
return keywords_textrank1, keywords_textrank2
|
tf-idf
·词频(term frequency, tf) 指的是某一个给定的词语在该文件中出现的频率
·你想文档频率(inverse document frequency, idf)是一个词语普遍的重要性度量,某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10底的对数得到
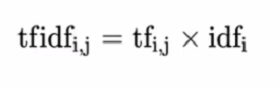

·关键字的提取代码:
1
2
3
4
5
6
| def Tfidf_extract(corpus1, corpus2):
keywords_tfidf1 = jieba.analyse.extract_tags(corpus1, 15)
keywords_tfidf2 = jieba.analyse.extract_tags(corpus2, 15)
return keywords_tfidf1, keywords_tfidf2
|
统计数据
用两篇文章提取关键字的交集除关键字的并集,得到一个简单的相似度分析
统计数据的代码:
1
2
3
| def count_word(A, B):
return round((len(set(A).intersection(set(B)))/len(set(A).union(set(B)))), 4)
|
完整代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
import jieba.analyse
corpus1 = "今天是星期日,中午我买了一个鸡腿"
corpus2 = "今天是星期一,中午我买了一杯可乐"
def testRank(corpus1, corpus2):
keywords_textrank1 = jieba.analyse.textrank(corpus1, 15)
keywords_textrank2 = jieba.analyse.textrank(corpus2, 15)
return keywords_textrank1, keywords_textrank2
def Tfidf_extract(corpus1, corpus2):
keywords_tfidf1 = jieba.analyse.extract_tags(corpus1, 15)
keywords_tfidf2 = jieba.analyse.extract_tags(corpus2, 15)
return keywords_tfidf1, keywords_tfidf2
def count_word(A, B):
return round((len(set(A).intersection(set(B)))/len(set(A).union(set(B)))), 4)
corpus_ran1, corpus_ran2 = testRank(corpus1, corpus2)
corpus_tif1, corpus_tif2 = Tfidf_extract(corpus1, corpus2)
print("相似度:", count_word(corpus1, corpus2))
print("相似度:", count_word(corpus_tif1, corpus_tif2))
|